

SSL 证书
数字证书
安全运维
域名
企业服务
SSL 证书
数字证书
安全运维
域名
企业服务
博客 > 网安学术|基于集成学习的多特征网络流量检测
浏览量:3200次评论:0次
作者:锐成网络整理时间:2024-08-12 16:41:03
摘 要:由于单一特征分类方法难以满足当前高效率、准确的网络安全维护要求,提出了一种基于集成学习的多特网络流量分类方法,通过综合利用流量数据中的多特征来提高分类的准确性和效率。首先,分析了网络流量中的多种特征,包括流量统计特征和原始字节流特征等。其次,结合集成学习模型进行多特征流量分类,对 LightGBM 进行二分类和多分类的准确率分别达到 99.3%和 99.0%。与没有进行特征提取的模型效果相比,所提方法的效果有显著的提升。最后,选择效果好的特征进行融合检测,发现检测效果有所提升。
内容目录:
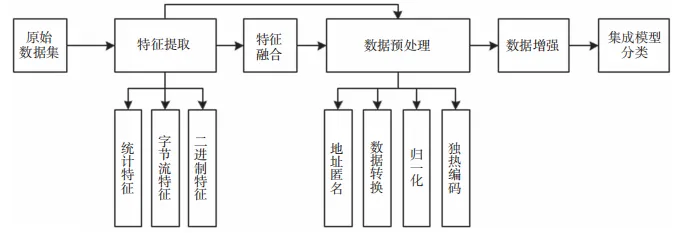
1 网络流量特征
1.1 统计特征选择
1.2 包特征提取
1.3 字节流特征提取
2 数据增强和集成学习
2.1 数据增强
2.2 集成学习
3 实验和结果分析
3.1 数据集
3.2 评价指标
3.3 实验环境
3.4 实验与处理
3.5 特征融合
3.6 实验结果和分析
4 结 语
随着互联网技术的迅速发展和网络应用的日益增多,网络流量呈现出前所未有的复杂性。网络流量分类作为网络安全的监控技术,重要性日益突出,其中利用流量中多特征的信息进行恶意流量识别成为一种有效的方法。针对这一方法,最近几年集成学习在网络流量检测领域得到了广泛关注和应用。集成学习首先结合多个分类器的输出,利用集成学习策略来提高分类器的泛化能力和鲁棒性,其次利用多特征提升网络流量分类的准确度。不同特征在不同的网络环境和攻击场景下也会表现出不一样的效果,因此需要考虑多种特征并进行合理的组合和筛选。Shekhawat 等人 讨论了特征分析的重要性,并提出了一种基于机器学习的特征分析方法,以获取特征相关信息。这一方法相比于依赖人类专业知识的方法更为可靠,且能够揭示特征之间相对不直观的交互作用。
特征提取的目标是从原始数据中提取出对分类或回归任务有用的特征,以便算法能够更好地理解和学习数据的模式。本文针对不同特征使用不同的提取方法。针对字节流特征使用基于数据包字节的卷积神经网络(Packet Bytes-based Convolutional Neural Network,PBCNN)的方法进行提取,针对包特征使用从数据包中提取的方法。
本文提出一种结合多特征在集成学习策略下的网络流量分类方法。此外,使用数据集 CICIDS2017的主要特征训练数据集,然后再使用 CICIDS2018数据集进行对比来验证所提方法。
1 网络流量特征
特征提取可以将原始的网络流量数据转换为易于理解和解释的特征表示形式,使得人们能够更直观地理解数据的含义和特点,进而进行可视化分析并解释结果。特征提取也是网络流量分类检测必不可少的一个重要环节,特征的提取是本文所提模型进行分类任务的关键,决定了模型进行训练的训练集和测试集的主要构成结构。
1.1 统计特征选择
针对统计特征的选择,首先计算每个特征与目标变量“Label”(代表网络行为是否正常)的相关系数,其次基于皮尔森相关系数计算相关系数,这是衡量两个变量线性关系强度的统计方法。皮尔森相关系数公式为:
式中:r 为相关系数,用于度量两个变量 X 和 Y 之间线性相关程度的统计量;n 为观察点的数量;为变量 X 的第 i 个观察值;
为变量 Y 的第 i 个观察值;
为变量 X 的平均值;
为变量 Y 的平均值,且相关系数介于 -1 和 1 之间。
通过分析,笔者筛选出了与目标变量相关性最强的 30 个特征。这一选择基于假设:与目标变量强相关的特征更有可能提供区分不同恶意攻击类别的重要信息。
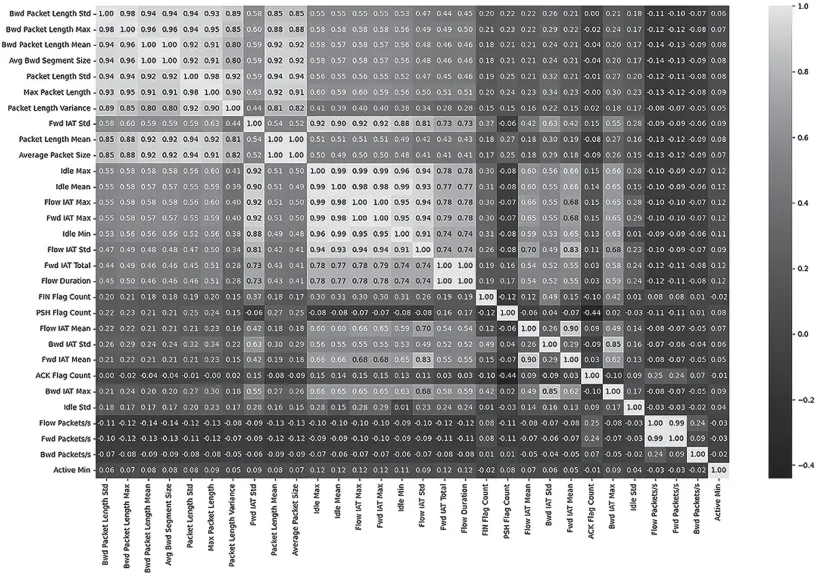
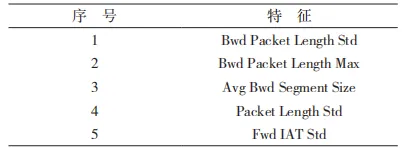
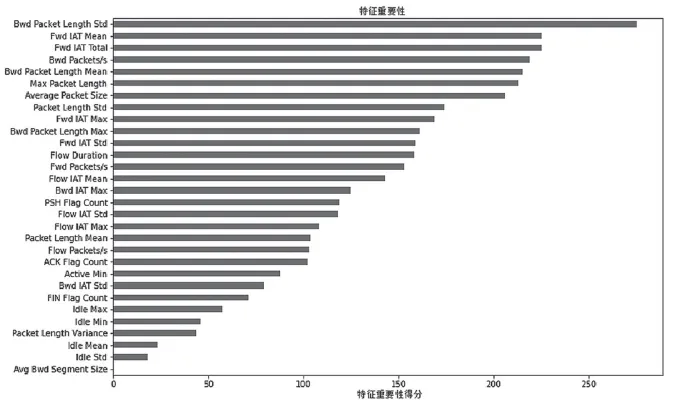
在可视化分析中,本文进一步通过热力图展示这些特征之间的相关性,从而更加直观地呈现数据之间的关系。热力图不仅可以展示单个特征与目标变量的相关性,还可以展示特征之间的相互关系,这有助于识别潜在的多重共线性问题。热力图如图 1所示。综合考虑确定了选择的特征,其中选择的部分特征如表 1 所示,各个特征的权重如图 2 所示。
图 1 统计特征热力图
表 1 部分统计特征的选择
图 2 各个特征权重
1.2 包特征提取
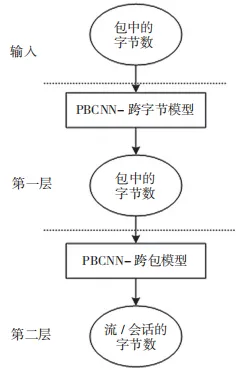
针对字节包特征的提取,本节使用 PBCNN 的方法实现,这是一种分层的基于字节的数据包卷积神 经 网 络(Convolutional Neural Network,CNN)。第 1 层从原始 PCAP 文件的数据包中的字节自动提取抽象特征,然后第 2 层从流量或会话中的数据包进一步构建表征,而不是使用特征就绪的 CSV 文件,以充分利用原始数据信息。多个卷积池模块通过对字节大小合适的多个过滤器进行级联,并通过一层TextCNN 获得流量的表示,将该表示反馈给 3 层全连接网络进行入侵分类。PCAP 文件包含了网络流量的原始数据包,这些数据包记录了网络上的数据流和交换信息。PACP 包形式如图 3 所示。PBCNN的流程如图 4 所示。
图 3 PACP 包形式
图 4 PBCNN 的两级层次
此方法将 PCAP 文件中的原始十六进制代码映射为 0 到 255 的等长十进制数。数据转换的目的是处理会话数据为深度学习模型所接受的输入格式。此步骤包括匿名化、数字编码及统一会话示例中的字节数和数据包数。网络流量数据中的地址包括MAC 源地址和目的地址,以及 IP 源地址和目的地址,原始流量数据中包含的 MAC 地址和 IP 地址不承载可以区分流量类型的特征,但是容易使模型产生偏差,故对 MAC 地址和 IP 地址进行匿名化处理。也就是说,模型可能只根据地址来确定会话样本类别。处理这个问题的方法是将地址匿名化,可以用相同长度的随机数代替,也可以将所有地址设置为相同的地址。在本文中选择了后一种处理方法。
第 1 步,将 MAC 地址替换为 0:00:00:00:00:00:00,IP 地址替换为 0.0.0.0。
第 2 步,首先进行数据编码,因为原始数据包中的数据是字节类型的,的数据是字节类型的,把这些数据编码成十六进制字符串并存储到数据库中,这一步骤是为了将原始字节数据转换成一种统一的格式,便于后续处理。其次进行类型转换,由于深度学习模型只接受数值型数据,因此需要将字节类型的数据转换为数值型数据,在这个过程中每个字节(8 位)可以代表一个从 0 到 255 的数值范围,这与图像中的像素值一致,作为模型的输入有利于之后的特征学习。最后,根据数值的最大和最小值进行归一化处理。此外,数据标签是字符类型的,需要数值编号,然后通过one-hot 编码处理成一个 15 维的 0 或 1 向量。
第 3 步,将十六进制数据转换成数值型数据,范围从 0 到 255,类似于图像中的像素值的过程,而深度学习模型只接受数值型的数据,0 代表黑色,是最暗的颜色值,255 则是最亮的颜色值,两者之间的是从黑到白的不同灰度等级,因此可以将这些数值的灰度图用来识别和检测,使之适用于深度学习模型的输入格式。
1.3 字节流特征提取
原始网络流量 通常以 PCAP 格式存储且原始流量的长度不一致,不能直接输入神经网络模型,故需要对输入的原始数据进行预处理。预处理的主要流程有流量拆分、特征构造及数据填充和截断。对 PCAP 文件进行处理以提取所需信息。PCAP 文件没有规定区分数据包的字符串,而是根据每个包头的 Caplen 定义数据区的长度得到下一个数据帧的位置,因此需要对原始流量数据进行拆分和提取,使用 Python 的 Scapy 库拆分 PCAP 包,提取原始流量信息。原始流量数据中包含的 MAC 地址和 IP 地址不承载可以区分流量类型的特征,但是容易使模型产生偏差,故对 MAC 地址和 IP 地址进行匿名化处理。将经过上述处理得到的十六进制数据信息每两位一个字节且对应 0 ~ 255 的灰度数值转换为十进制信息,每个字节的十进制数表示一个流特征。然后,利用全 0 填充的方式将不同数据包之间的字节长度填充或截断到相同长度,最终生成流的特征和类别标签构成的待选特征数据集。
2 数据增强和集成学习
2.1 数据增强
为了解决数据不平衡问题,本文使用了 K-means+SMOTE 的方法平衡数据集,以增强模型的泛化能力。其中,成少数类过采样技术(Synthetic Minority Oversampling Technique,SMOTE)被用来合成样本,主要参数是 k,由其确定多少个最近相邻样本生成新样本。给定一个少数样本 x 和 k 个最近相邻样本生成合成样本
式中:i 为一个随机选择的邻居,λ 为一个介于 0 和1 之间的随机数,控制了新样本在x和之间的位置。
2.2 集成学习
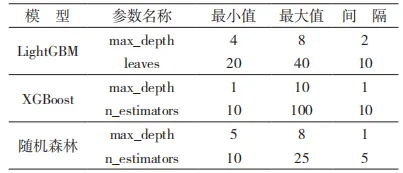
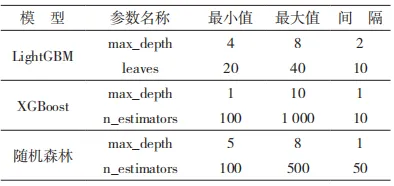
本文选取了随机森林、LightGBM 和 XGBoost[7]这 3 种集成模型,通过结合数据增强的方法对不同特征进行网络流量检测,并且将这些不同特征同时进行检测以对比效果,确定出最适合网络流量检测的方法。其中,参数的选取极为重要,本文通过GridSearchCV 方法进行参数的选取。首先定义一个参数网格 ,LightGBM 中“max_depth”是决策树的最大深度,本次选取 4,6 和 8 作为选取对象,“leaves”是树中叶子的最大数量,定义的尝试值为20,30 和 40。将准确率作为评分标准,也就是模型正确预测的比例,在预测之前会把数据集分为 5份,模型将进行 5 次训练,每次用不同的一份作为测试集,其余的作为训练集,以此来进行评估。在每一组参数下通过交叉验证评估模型性能,也就是每一组参数组合都会使用不同的训练集和测试集多次评估;再计算所有轮次的平均得分,从而在一定程度上减少模型性能的随机性和偶然性,让模型结果更加可靠和稳定;最后确定参数用于模型的建立。在不同模型中选取的数值也不一样,在多分类中也是跟二分类不一样,二分类选取参数的范围如表 2所示,多分类如表 3 所示。
表 2 二分类模型参数设置
表 3 多分类模型参数设置
3 实验和结果分析
3.1 数据集
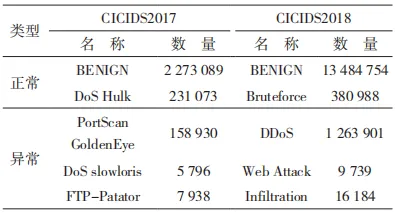
为了验证本文提出方法的可靠性,使用了公共数据集 CICIDS2017 和数据集 CICIDS2018 进行验证。数据集中的一些样本数量如表 4 所示。
表 4 数据集部分特征
3.2 评价指标
本实验采用总体准确率、查准率、召回率、F1值来作为评估性能的指标。
3.3 实验环境
硬件环境:Intel (R)Core(TM)i7-10870H CPU@ 2.20 GHz 处 理 器,32 GB 内 存,GPU(GeForceGTX3080)计算机运行。
软件环境:Win11 系统。在 Python3.7 语言中,在 PyCharm 环境下使用张量 frow1.15.0 作为后端,使用 Keras 2.3.1 中的深度学习库实现分类操作,使用 tensorflow 2.8.0 和 Torch1.3.1+CPU 实现操作。
3.4 实验与处理
首先在第 1 节介绍了关于从原始 PACP 包进行特征提取的简单说明和之后对提取出来的数据进行预处理,其次用第 2 节中的数据增强的方法对数据进行平衡化处理,再放到集成学习模型中进行检测,最后把 3 个特征进行融合,与单个特征检测结果进行对比。本文实验使用的数据集中,测试集和训练集分别占比 20% 和 80%。实验流程如图 5 所示。
图 5 实验流程
3.5 特征融合
首先是统计特征和包特征的融合,经过特征筛选和维度统一,将包特征和统计特征在输入模型之前就合并为一个统一的特征向量。例如,将所有特征标准化或归一化,然后将它们并排放置在同一个特征向量中。例如包特征表示为数组 [2 3 4],统计特征表示为数组 [0.6 0.8],合并之后就是 [0.6 0.8 2 3 4],再把这些数组转换为一维的,因为选取的每个会话数为 20 个数据包,每个包 256 字节,所以也就是每 256 字节数据与统计特征的 30 维 240 个特征信息直接拼接在一起。如果超过了 256 字节,则丢弃多余的部分,不足 256 字节的则补 0,最后组合为一维数组放到模型中进行分类。
拼接字节向量及其隐藏状态,经由线性变换可得相应位置的特征,即:
式中:为字节特征表示,
为字段特征,采用一种全局混合池化方法,该方法结合了全局平均池化和全局最大池化,能够提取数据包负载长度的特征和负载内容的特征,具体过程为:
式中:α 的元素介于 0 到 1之间;向量表明位置ij 的字节分布情况和字段的存在情况;向量
表示提取的数据包特征。
在统计特征和字节流特征中,为了确保特征融合之后模型检测的效果不出现过拟合,在进行多特征融合之前需要对特征进行统一的转换,以确保接下来特征融合时的检测。采用零填充的方法和特征标准化的方法进行特征形式统一,在第 3 节中介绍过相关方法,此处使用相同的方法。
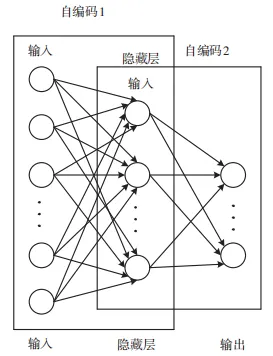
数据首先通过一个编码器函数转换到一个隐藏层,其次通过一个解码器函数转换回输出层,目标是使输出尽可能接近输入。在去噪自动编码器(Denoising Autoencoder,DAE) 中, 输 入 数 据 在进入编码器之前会被故意加入噪声。让自编码器学习去除输入数据中的噪声并恢复原始的信号,可以让模型检测的准确率有所提升,也可以帮助模型学习到数据中更有用的特征。堆叠去噪自动编码器(Stacked Denoising Autoencoder,SDAE)是通过堆叠多个 DAE 构成的,每一层都学习输入数据的更深层次特征。在训练过程中,首先单独训练每一个DAE,其次将它们按顺序堆叠起来。在 SDAE 中,每一层的隐藏输出都作为下一层的输入。
输入层表示为向量 x,隐藏层的输出表示为向量 h,从输入层到隐藏层的权值表示为矩阵 W 和向量 b。向量 b 表示偏差项,定义 f 为激活函数。
同样,将输出层的输出定义为向量 y,从隐藏层到输出层的权值表示为矩阵 W' 和向量 b'。向量 b'由偏差项组成。本文还定义 f ' 为激活函数。使用式(6)计算从隐藏层到输出层的数据传播。
自动编码器确定均衡输入 x 和输出 y 的权重 W和 W'。权重使用式(7)计算,它使输入数据和输出 y 之间的差异最小化。
使用自动编码器可以减少数据向量的维数。h的维数小于x 或 y,利用机器学习的输出向量 h 作为隐藏的特征向量,然后通过重叠 1 个隐藏层作为第 2 个自动编码器的输入来合并多个自动编码器,如图 6 所示。
图 6 一个堆叠自编码器结构
先经过 SDAE 的高级特征表示,再把字节流特征和统计特征进行拼接,放到集成学习的基分类器中进行训练,最后用随机森林、XGBoost 和LightGBM 模型进行分类。
因为本节提取的统计特征是每个特征占据 8 个字节,每一行的数据总字节数是 240 个,统计特征一共筛选出 30 维,所以将相对应的特征输出,将输出的高维特征与选取统计特征进行拼接。
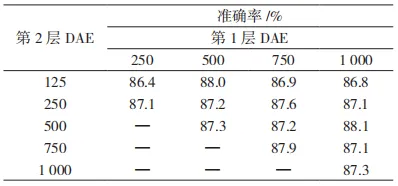
在字节流特征中,因为确定了每个流中的长度为 20 个数据包的大小,使用 SDAE 的方法,对隐藏层的大小进行最终的确定。在消融实验中,首先在第 1 层 DAE 中选定 250、500、750 和 1 000 的隐藏单元数(nhid)值,在第 2 层中选定同样的特征,但是第 2 层的特征数量不可能超过第 1 层的数量。实验结果如表 5 所示。
表 5 选取不同 nhid 长度时的实验结果
从实验结果来看,第 1 层选取 1 000、第 2 层选取 500 与第一层选取 500、第二层选取 125 相比,基本没有太大的差别,但是考虑到运算时间的问题,所以本节选取第 1 层 500 和第 2 层 125 的数值进行实验。
3.6 实验结果和分析
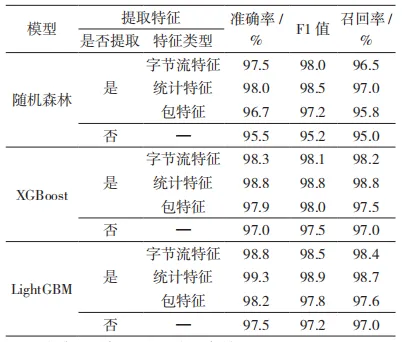
为了验证本文方法的有效性,将本文方法与没有进行特征提取的方法进行二分类对比实验。首先与直接使用 k-means+SMOTE 和集成学习的模型进行对比。分类结果如表 6 所示。
表 6 各个模型中二分类结果
由表 6 可知,对于随机森林、XGBoost 和 LightGBM这 3 种模型,进行特征提取后无论是在准确率、F1值还是召回率上都有更好的性能表现,证明了本文所提特征提取工作的有效性。但是,不同类型的特征对模型性能有不同的影响。在大多数情况下,使用统计特征时,所有模型都呈现了较好的结果,这可能是因为统计特征能更全面地捕捉数据的特性。相比之下,使用包特征和字节流特征时,模型的性能表现一般。然而,在所有模型中,LightGBM 在处理经过良好特征工程的数据时,显示出最佳的性能。
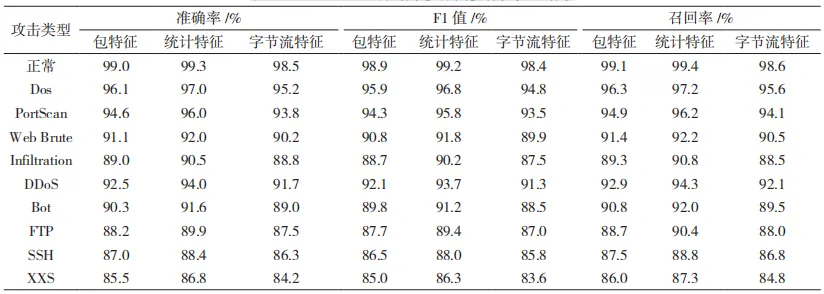
因为确定了 LightGBM 的有效性并且为了展示本文所提方法的时效性,接下来将在 LightGBM 模型下对数据集 CICIDS2018 进行多种攻击类型的检测,检测结果如表 7 所示。
表 7 CICIDS2018 数据集多分类多特征检测结果
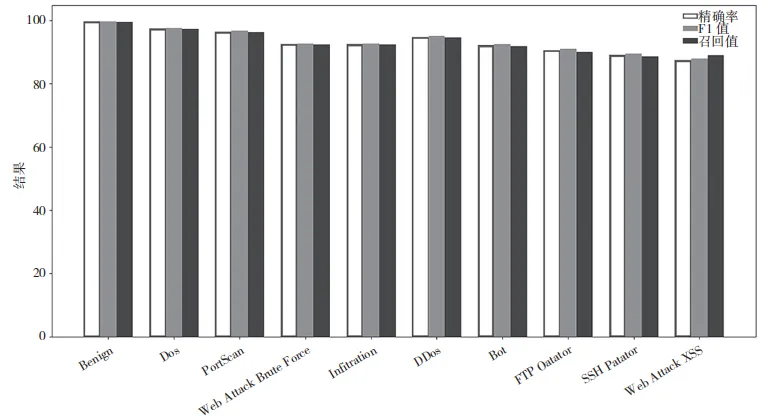
使用包特征进行攻击检测的结果表明,在某些情况下表现较差,尤其是对于较为复杂的攻击类型,如 Web 攻击和 Infiltration 攻击,这可能是因为包特征相对较简单,可能不足以捕获复杂攻击的全部特征。使用字节流特征的检测结果普遍比使用包特征的好,表明字节流特征提供了更丰富的信息,有助于改进对网络攻击的识别。统计特征在多数攻击类型的检测上表现更好,尤其是对于 DoS、PortScan和 FTP-Patator 等攻击,这表明统计特征能够更好地概括数据集的统计属性,为模型提供了更有效的信息。因此,本文设计实验对两种特征进行融合检测,以验证是否拥有更好的检测效果。实验结果字节流和统计特征的融合值如图 7 所示。
图 7 字节流和统计特征融合特征多分类检测结果
从图 7 的实验结果可以看到,在几乎所有攻击类型中,融合特征的性能普遍高于单独使用任一类型的特征。这表明,当不同类型的特征结合起来时,它们能够提供比单独特征更全面的信息,从而提高模型的预测能力。这是因为不同类型的特征可能从不同的角度描绘数据,它们的结合能够提供更完整的数据视图,通过结合不同来源的特征,可以显著提高网络流量分类和攻击检测的准确性。特征融合有助于捕捉更丰富的上下文信息和隐藏模式,从而提高模型的泛化能力和鲁棒性,说明了本文所提方法的有效性与可行性。
4 结 语
本文针对网络流量分类中恶意流量识别的问题,提出了一种基于集成学习和多特征检测的方法。随着网络环境的日益复杂化,单一特征已经难以满足对网络安全的监控需求,因此,利用多种特征进行融合处理成为提升恶意流量检测准确性的关键途径。首先,本文指出了统计特征、字节流特征和包特征在网络流量分类中的重要性。其次,通过计算特征与目标变量的相关性,筛选出有助于区分正常与异常流量的关键特征。本文的主要贡献如下:
(1)通过进行特征提取,成功地提升了模型的检测性能;
(2)通过实验对比与参数的调优,确定了最佳分类模型,为网络流量检测提供了可行的解决方案。未来将进一步探索数据的其他类型特征,结合集成学习中不同基分类器对特征的影响,进一步提高模型的性能和鲁棒性。
引用格式:吴苏亚 , 丁要军 . 基于集成学习的多特征网络流量检测 [J]. 通信技术 ,2024,57(7):731-738.
作者简介 >>>
吴苏亚,男,硕士研究生,主要研究方向为网络安全、机器学习、网络流量分类;
丁要军,男,博士,教授,主要研究方向为网络安全、机器学习、网络协议识别
选自《通信技术》2024年第7期(为便于排版,已省去原文参考文献)
重要声明:本文来自信息安全与通信保密杂志社,经授权转载,版权归原作者所有,不代表锐成观点,转载的目的在于传递更多知识和信息。
相关文章推荐
2025-06-12 16:26:36
2025-04-22 15:15:30
2025-04-21 15:20:03
2025-04-02 16:28:39
2025-03-27 15:01:53
热门工具
标签选择
阅读排行
官方咨询热线:400-002-9968
官方邮箱:business@racent.com
地址:上海市普陀区真南路1199弄智创Top8号楼602A单元

商务合作:business@racent.com
投诉意见:media@racent.com
代理域名注册服务机构:成都西维数码科技有限公司 北京新网数码信息技术有限公司 阿里云计算有限公司




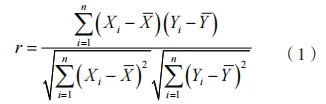

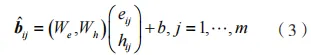







我的评论
还未登录?点击登录